4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layer-wise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
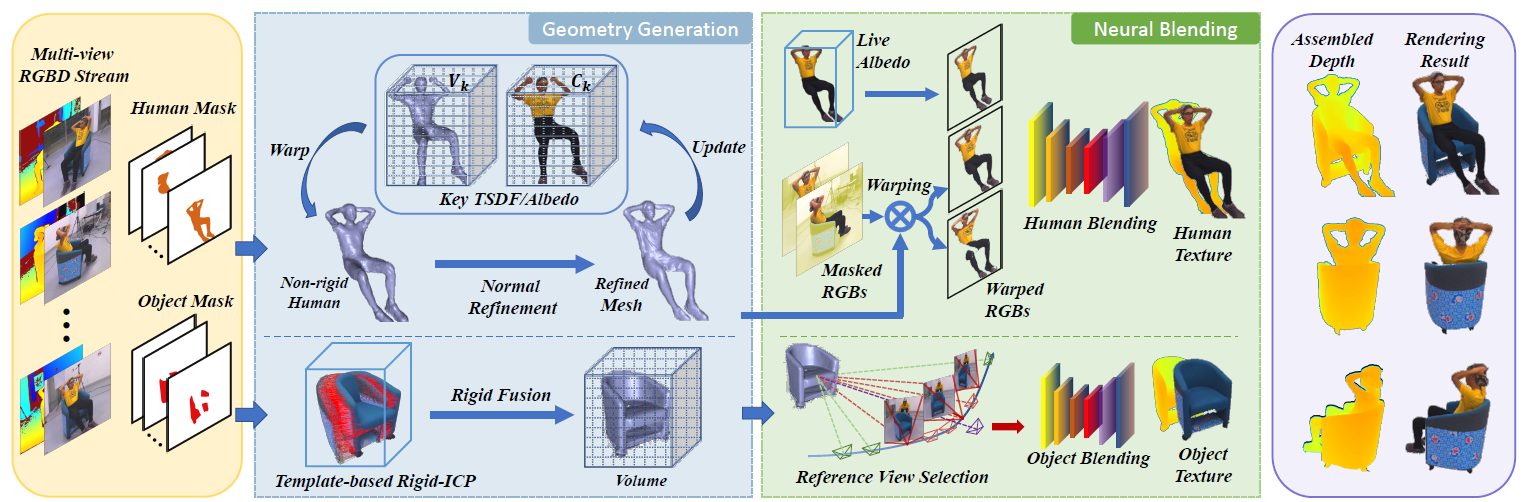
Pipeline
NeuralHOFusion includes two streams for human and objects separately, and each stream includes two steps: Geometry Generation and Neural Blending. Our key idea is to organically combine traditional volumetric non-rigid fusion pipeline with recent neural implicit modeling and blending advances, besides embracing a layer-wise scene decoupling strategy.
Result
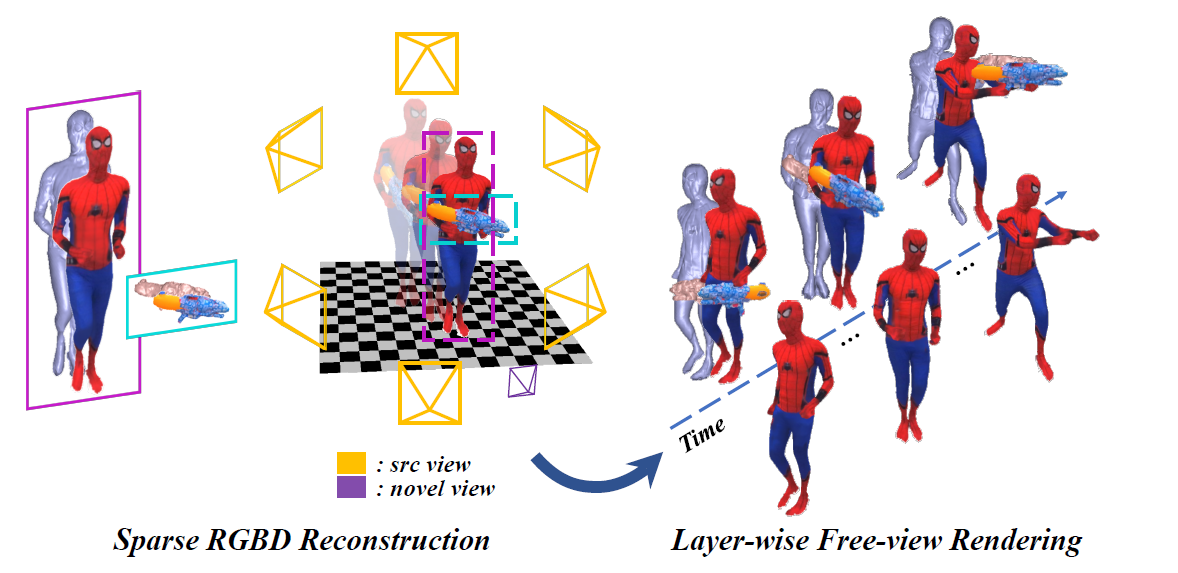
Our NeuralHOFusion achieves layer-wise and photorealistic reconstruction results, using only 6 RGBD cameras. Our approach handles various complex human-object interaction scenarios and even multi-person interactions. It achieves photo-realistic layer-wise geometry and texture rendering in novel views for both the performers and interacted objects.
Results
